#TodayILearned that Cinderella’s slippers may have been squirrel fur (‘vair’) rather than glass (‘verre’)
CINDERELLA’S SLIPPERS: GLASS OR SQUIRREL FUR?


Sir Keir/Kier Starmer needs to be Prime Minister for at least 10 years for me to have any hope of me spelling him with any confidence, or even with any consistency

When Kier Starmer gets on the blower and asks me what he should do in government, I shall tell him to make February the 29th a Bank Holiday
It’s a suitably cautious policy and I commend it to the house.

#TodayILearned the phrase "cheese it-the cops!"
#TodayILearned the phrase cheese it-the cops!
“A warning that the police were coming. “Cheese” might be a variant of “cease.” It might also come from the cheese course coming at the end of dinner; in the sense that with nothing else ahead, it’s time to leave. In either event, “cheese it—the cops!” was a staple of mid-20th-century crime novels and films, as well as such movies as The Dead End Kids and The Bowery Boys.”
If you squint hard enough, and use your imagination, you can just about make out the ruins of Sherbourne Old Castle, which belonged to Sir Walter Raleigh, the bloke who was supposed to have brought tobacco to Europe, but maybe didn’t

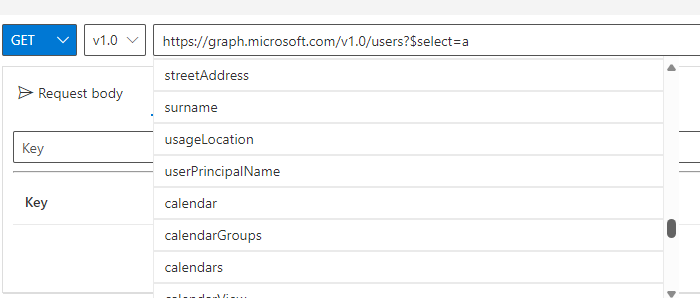
#TodayILearned that one way of getting a list of data available from Microsoft Graph API is to type ‘graph.microsoft.com/v1.0/user… into Graph Explorer, and see what show’s up in the Dropdown
I bought an old postcard of my chums from Salisbury Museum - the Giant and Hobnob. I’m just about old enough to have seen them going through the City

Agree with virtually every word of this
A more sympathetic take on Chelsea’s defeat
#cfc #ChelseaFC ⚽
Vim commands to write out parameter list
Executive summary :)
For each line
0
D
PP
From the colon prompt:
%s/^ */ write-dbg "`
%s/ *\$/: <\$
%s/$/>"
%s/,//g
The gory details
Starting with a parameter clause like this:
Param(
$Parameter1,
$Parameter2,
$Parameter3,
$Parameter4
)
The manual bits
First, take off the ‘Param(i’, and the bracket at the end
Second, for each line do this:
0
D
PP
… to get:
$Parameter1, $Parameter1,
$Parameter2, $Parameter2,
$Parameter3, $Parameter3,
$Parameter4 $Parameter4
The colon prompt bits
Replace spaces at the front with the write-dbg, a double-quote, and then a backtick. The backtick is because I need to escape the name of the variable
:%s/^ */ write-dbg "`
This gives:
write-dbg "`$Parameter1, $Parameter1,
write-dbg "`$Parameter2, $Parameter2,
write-dbg "`$Parameter3, $Parameter3,
write-dbg "`$Parameter4 $Parameter4
Replace the spaces between the repeated variables with ‘: <’
:%s/ *\$/: <\$
….giving:
write-dbg "`$Parameter1,: <$Parameter1,
write-dbg "`$Parameter2,: <$Parameter2,
write-dbg "`$Parameter3,: <$Parameter3,
write-dbg "`$Parameter4: <$Parameter4
End the string:
%s/$/>"
….which gives:
write-dbg "`$Parameter1,: <$Parameter1,
write-dbg "`$Parameter2,: <$Parameter2,
write-dbg "`$Parameter3,: <$Parameter3,
write-dbg "`$Parameter4: <$Parameter4
Finally get rid of the commas
%s/,//g
Leaving:
write-dbg "`$Parameter1: <$Parameter1>"
write-dbg "`$Parameter2: <$Parameter2>"
write-dbg "`$Parameter3: <$Parameter3>"
write-dbg "`$Parameter4: <$Parameter4>"
#TodayILearned that in 1929, the USSR replaced the 7 day week with a 5 day week, with a fifth of the workforce resting on any given day
This was a good episode to listen to in Leap Week :) 🎙️
Lee Anderson MP thinks that Sadiq Khan is “controlled by Islamists”
I think Lee Anderson is controlled by idiots
I just saw Wicked Little Lies….absolutely adored it. It won’t be everybody’s cup of tea, but probably my favourite film so far this millennium! 🎥
It’s worth avoiding spoilers

We had a lovely, long lunch yesterday at the Lahore Kebab House, just off the Commercial Road
On 10cc
I listened to the Word in your Ear podcast about 10cc and it occurred to me that I really like one of their number ones, and really, really, really dislike one of their others
The disparity of my feelings is greater than that for any two hits of any other band
The songs are ‘I’m Not in Love’ and ‘Dreadlock Holiday’, in that order 🎵
#TodayILearned that Lloyd Cole, of the Commotions, and Perfect Skin, is Chelsea 🎵⚽
I’ve been told that, ergonomically, the top of your monitor should be level with your eyes.
I’m sure this is good advice, but I’m wondering if it applies to people who live on the command line, because on the command line stuff tends to happen at the bottom of the screen #Powershell
I think my work laptop is being converted to Windows 11
I think ‘trepidatious’ is the word for how I’m feeling right now

Watched Catch Me if You Can. I really enjoyed it, and my enjoyment wasn’t at all marred by discovering that the ‘true story’ on which it was based has been called into question. It seems quite fitting.


How to post to a test micro.blog from powershell
Sorry about the formatting of this post…I’m having trouble getting markdown not to convert the url to markdown links, even within code blocks
There’s a bit more detail on posting generally from powershell at mattypenny.micro.blog/2024/02/1…
This is the standard bit
$Token = 'whatever-the-token-is' | ConvertTo-SecureString -AsPlainText -Force
$Body = @{ content = 'Testing again. 1 , 2, 1, 2' h = 'entry' 'post-status' = 'draft' }
You then put ‘?mp-destination=’ followed by the URL of the test micro.blog on the end of the base URL as in the gist below. (The markdown conversion is nausing up the URL if I type it in here - sorry!
invoke-restmethod micro.blog/micropub -Method post -Authentication Bearer -Token $Token -Body $Body
url preview edit
mattypenny-test.micro.blog/2024/02/1… micro.blog/account/p… micro.blog/account/p…
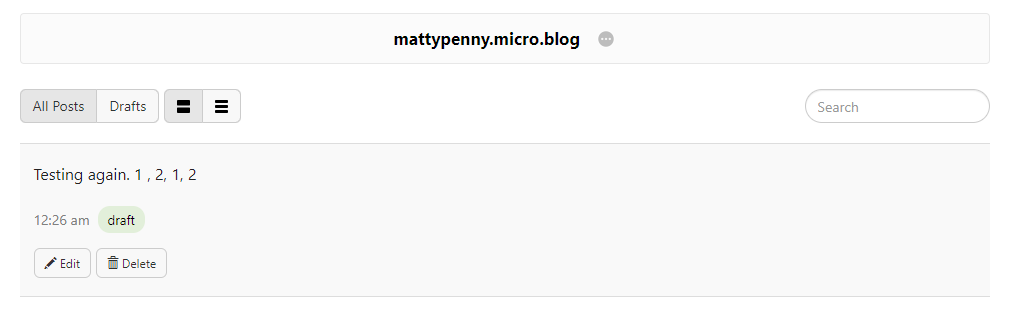
The output confirms that the post has gone to mattypenny-test.micro.blog

How to post to micro.blog with powershell
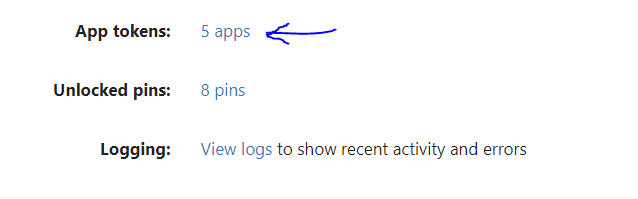
Get the token
Go to the account page in micro.blog, scroll down to the bottom where there is ‘App tokens’ and click on the link which has the text ‘5 apps’ (or however many apps you’ve authorized)
Pick an app name (I went wild with my imagination and called it Powershell), and click on ‘Generate Token’

Reveal the token and Ctrl-C it.
Do the powershell bit
Convert the token into a securestring
$Token = 'whatever-the-token-is' | ConvertTo-SecureString -AsPlainText -Force
Set up the $Body
$Body = @{
content = 'Testing again. 1 , 2, 1, 2'
h = 'entry'
'post-status' = 'draft'
}
You need the quotes around ‘post-status’ because Powershell doesn’t like hyphens in variable names. I’m keeping this post as draft, because the content is even less interesting than my other posts
Then call invoke-restmethod as follows:
invoke-restmethod https://micro.blog/micropub -Method post -Authentication Bearer -Token $Token -Body $Body
…and Bob’s your uncle
There is, clearly, a lot more really basic stuff that I need to work out:
-
how to create a title
-
how to make the URL more meaningful (tbf, I don’t know how to do that through the browser as yet)
-
how to attach a photo
-
how to post to the testing blog rather than the default one
Then, I’d like to:
- create a function to select a particular post, download it, edit in in vim or vscode, then post the new version